Gemma 4 Architecture Deep Dive: MoE, Dual RoPE, and 256K Context Explained
Gemma 4 Architecture Deep Dive: MoE, Dual RoPE, and 256K Context Explained
TL;DR: Gemma 4's 26B MoE variant packs 128 experts, activating only 8 plus 1 shared expert per token — just 3.8B active parameters that deliver 97% of the 31B Dense model's performance. Dual RoPE (standard RoPE + p-RoPE) enables the 256K context window, while Shared KV Cache lets the final N layers reuse earlier KV projections, saving significant memory and compute. These architectural innovations drove AIME scores from Gemma 3's 20.8% to 89.2%.
How does a model with only 3.8B active parameters beat one with 31B? The answer lies in Gemma 4's architecture.
When Google DeepMind released Gemma 4 in April 2026, they didn't just make the model bigger. They fundamentally changed how it works — replacing brute-force parameter scaling with smarter routing, and swapping naive full-context computation for elegant hybrid attention mechanisms.
This article breaks down Gemma 4's four major architectural innovations and explains why these design decisions make it the most impactful open-source model of 2026. If you're not yet familiar with Gemma 4's overall landscape, start with the Gemma 4 Complete Guide.
Evaluating whether Gemma 4's architecture fits your use case? Book a free AI architecture consultation and let our team help with technical assessment.
Gemma 4 Architecture Overview: Dense vs MoE — Two Design Philosophies
Gemma 4 ships with two fundamentally different architecture tracks: Dense and Mixture of Experts (MoE). This isn't just a size difference — it's a completely different design philosophy.
Dense architecture includes the E2B (2.3B), E4B (4.3B), and 31B models. Every parameter participates in every forward pass. The 31B Dense is the flagship: MMLU Pro 85.2%, AIME 89.2%, but requires roughly 18 GB VRAM.
MoE architecture has one model: the 26B A4B. Total parameters: 25.2B. Active parameters per forward pass: just 3.8B. MMLU Pro 82.6%, AIME 88.3% — achieving 97% of Dense performance at a fraction of the compute cost.
The two tracks serve different needs. If you want maximum quality and have the hardware, go Dense 31B. If you need the best performance-per-dollar on constrained hardware, the 26B MoE is the smarter choice.
| Feature | Dense (31B) | MoE (26B A4B) |
|---|---|---|
| Total Parameters | 31B | 25.2B |
| Active Parameters | 31B | 3.8B |
| AIME 2026 | 89.2% | 88.3% |
| MMLU Pro | 85.2% | 82.6% |
| Min VRAM (Q4) | ~18 GB | ~16 GB |
| Inference Speed | Baseline | 3-4x faster |
Let's dig into the MoE architecture's core design — how 128 experts collaborate.
Mixture of Experts (MoE): How 128 Experts Divide the Work
MoE isn't a new concept, but Gemma 4's implementation introduces several critical breakthroughs.
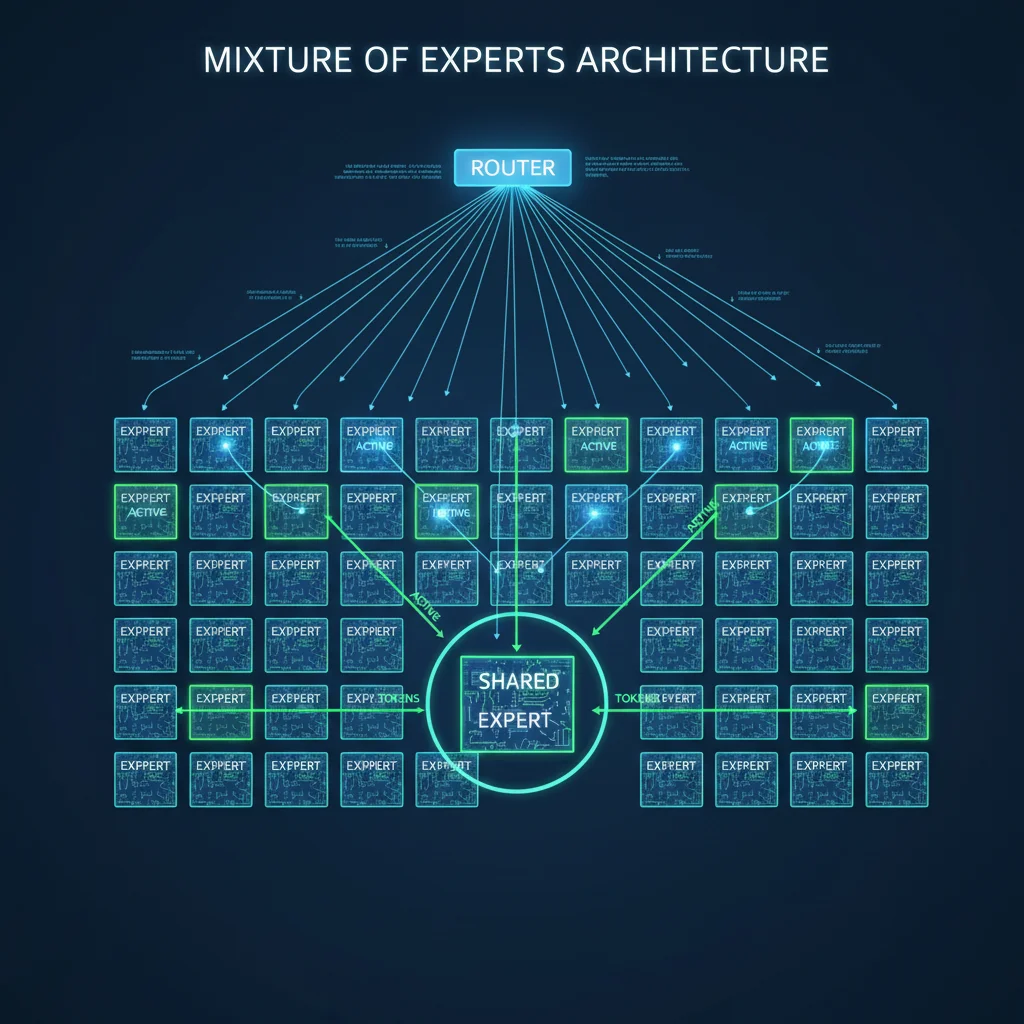
128 Small Experts + 1 Shared Expert
Traditional MoE models use 8-16 large experts. Gemma 4 goes the opposite direction — 128 small experts plus 1 shared expert. Why?
Finer-grained specialization. With 128 small experts, each one can become highly specialized in specific knowledge domains or linguistic patterns. The router scores each token against all 128 experts, then selects the top 8 for processing.
The shared expert is a crucial design choice. It doesn't participate in routing — it's always activated. Google designed it at three times the size of regular experts to store general knowledge. Think of it as the company's "general affairs department," while the 128 small experts are specialized divisions. Every token gets processed by the general department plus the 8 most relevant specialized ones.
How Routing Works
The router is a linear layer followed by softmax. Each token's hidden state passes through the router, producing 128 scores. The top 8 become that token's assigned experts.
Here's the key efficiency insight: despite 25.2B total parameters, only 3.8B are active per forward pass (8 selected experts + 1 shared expert). This means:
- Inference speed: Fast, because actual computation is small
- Memory usage: Loading requires all 25.2B parameters, but compute memory is sized for 3.8B
- Quality assurance: The diversity of 128 experts ensures broad coverage across input types
When I first saw the 26B MoE scoring 88.3% on AIME, I was genuinely surprised. 3.8B active parameters, less than one percentage point behind the 31B Dense? This validates an important principle: model quality depends more on how efficiently parameters are used than on raw parameter count.
Want to know what hardware you need for MoE inference? Check our Gemma 4 Hardware Requirements Guide.
Dual RoPE: The Secret Behind 256K Context Windows
The context window expanded from Gemma 3's 128K to 256K, but not through brute-force position encoding expansion. Gemma 4 uses a more elegant solution: Dual RoPE.
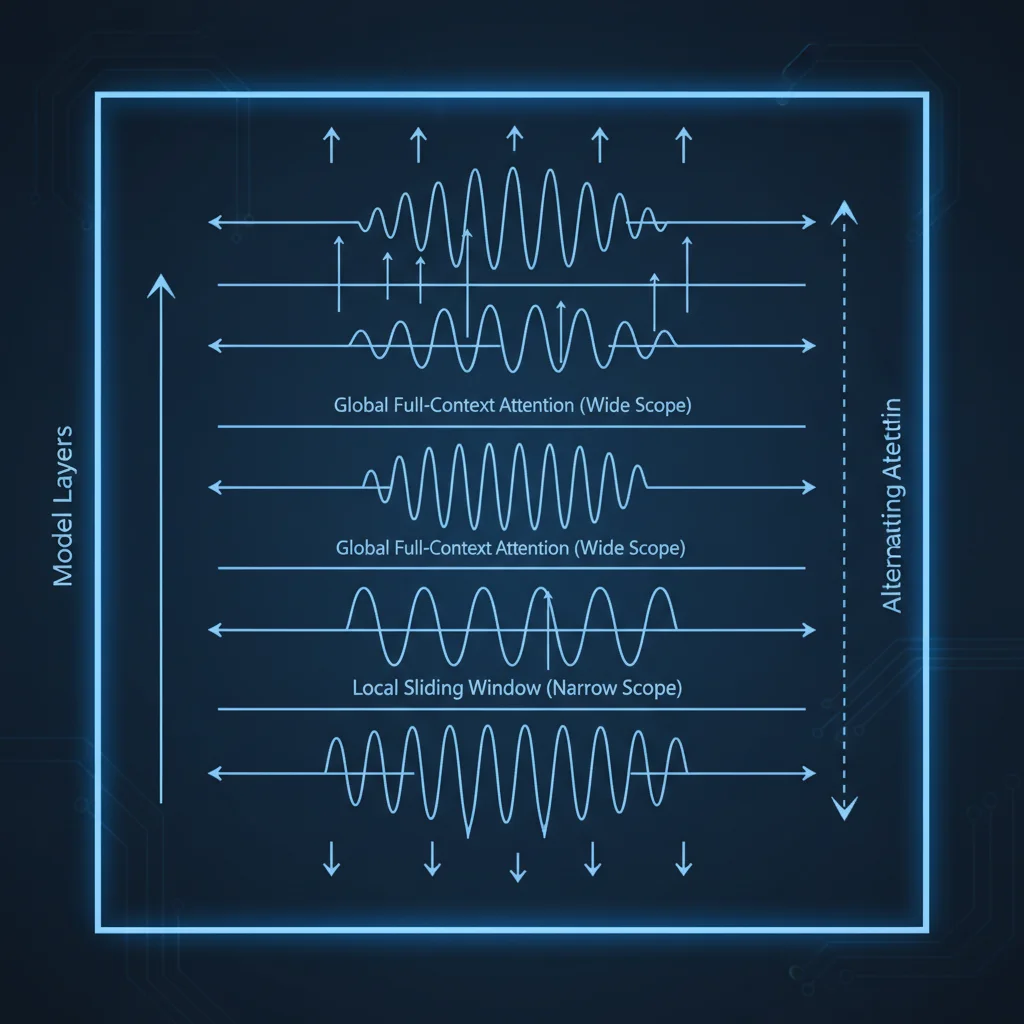
Alternating Attention Layers
Gemma 4's decoder layers alternate between two attention modes:
- Local Sliding Window Attention: Each layer attends to only 512-1024 neighboring tokens. Fast, memory-efficient, ideal for local context.
- Global Attention: Attends to every token in the entire context. Compute-intensive, but captures long-range dependencies.
The two layer types alternate, with the final layer always being global attention — ensuring the model's last representation has full awareness of the entire input.
Why Two Types of RoPE?
Here's the problem: standard RoPE (Rotary Position Embedding) degrades at extreme distances. When the distance between tokens exceeds what the model saw during training, position encoding extrapolation quality drops.
Gemma 4's solution is a dual-track approach:
- Sliding window layers: Use standard RoPE. Since the window itself limits token distance to 512-1024, there's no extrapolation issue.
- Global attention layers: Use Proportional RoPE (p-RoPE). p-RoPE adjusts frequency distribution so position encodings remain stable across ultra-long distances.
This is Dual RoPE — two different position encoding strategies within the same model, each serving its matching attention type.
Practical Impact
A 256K context window means you can feed in roughly 400,000 English words at once. For applications processing entire codebases, lengthy documents, or extended conversation histories, this is a substantial capability upgrade.
More importantly, quality doesn't severely degrade as context grows longer. This is Dual RoPE's core advantage over simply increasing the RoPE base frequency.
Shared KV Cache: The Key to Inference Acceleration
If MoE solves the "training efficiency" problem, Shared KV Cache solves the "inference efficiency" problem. This is arguably Gemma 4's most practically useful innovation for real-world deployment.
What Is KV Cache and Why Is It a Bottleneck?
During Transformer inference, every layer computes Key and Value matrices. These matrices get cached (the KV Cache) so the model doesn't recompute previous tokens when generating the next one.
The problem: a 256K context window makes the KV Cache enormous. Each layer stores its own K and V, and as layers pile up, memory explodes.
Gemma 4's Solution
Gemma 4 introduces Shared KV Cache: the model's final N layers stop computing their own K and V projections. Instead, they reuse KV tensors from the nearest preceding non-shared layer.
A critical detail: reuse respects attention type — sliding window layers only reuse KV from other sliding window layers, and global attention layers only reuse from other global layers. This prevents different attention mechanisms from interfering with each other.
Performance Impact
- Memory savings: Fewer KV projection parameters across N layers translates directly to lower memory usage
- Compute savings: Skipping KV projection matrix multiplications speeds up inference
- Quality impact: Google's ablation studies show negligible quality loss
For teams running 256K-token inference, this design is a real cost saver. Combined with quantization, the 26B MoE runs smoothly on consumer GPUs with 16 GB VRAM.
Per-Layer Embeddings (PLE)
Also worth mentioning is Per-Layer Embeddings — an additional embedding table that feeds a small residual signal into every decoder layer. This allows the model to learn different token representation offsets for different layers, further enhancing each layer's specialization.
Looking to deploy Gemma 4 on your existing infrastructure? Contact our AI architecture team for a customized deployment plan and cost estimate.
From Gemma 3 to Gemma 4: Architecture Evolution Compared

Placing Gemma 3 and Gemma 4 architectures side by side reveals that this isn't a simple version upgrade — it's a fundamental shift in design philosophy.
Architecture Differences at a Glance
| Feature | Gemma 3 | Gemma 4 |
|---|---|---|
| Architecture Type | Dense only | Dense + MoE dual-track |
| Largest Model | 27B | 31B Dense / 26B MoE |
| Context Window | 128K | 256K |
| Position Encoding | Standard RoPE | Dual RoPE (standard + p-RoPE) |
| KV Cache | Independent per layer | Last N layers shared |
| GQA Ratio | Higher KV head count | 8 Query : 1 KV (more aggressive) |
| Expert System | None | 128 experts + 1 shared expert |
| Per-Layer Embeddings | None | Yes |
| License | Google Terms of Use | Apache 2.0 |
| AIME 2026 | 20.8% | 89.2% (31B) |
| MMLU Pro | ~70% | 85.2% (31B) |
The Three Most Critical Changes
First, the introduction of MoE. Gemma 3 was Dense-only across the entire lineup. Gemma 4 offers MoE for the first time, letting developers achieve near-flagship performance with far less compute. This matters enormously for budget-constrained teams and edge deployment scenarios.
Second, attention mechanism optimization. Gemma 4 pushes GQA (Grouped Query Attention) to a more aggressive ratio — 8 Query heads sharing 1 KV head. Combined with Shared KV Cache, this dramatically compresses memory requirements during inference.
Third, context window doubling. From 128K to 256K, but not through brute force. Dual RoPE enables this expansion while maintaining quality. This is genuine engineering innovation.
The E2B's performance deserves special attention. Community benchmarks confirm this 2.3B parameter model outperforms Gemma 3's 27B on multiple tasks. That's 12x smaller in parameter count with better results. It clearly demonstrates that architectural innovation beats parameter scaling.
Want to compare Gemma 4's architecture against competitors? See our Gemma 4 vs Llama 4 vs Qwen 3 Comparison.
What These Architectural Innovations Mean for Developers
After all the architecture details, you might be wondering: how does any of this affect my actual work?
Dramatically Lower Deployment Costs
The MoE + Shared KV Cache combination means you can run the quantized 26B MoE on a single RTX 4090 (24 GB VRAM) and get near-31B Dense quality. In the Gemma 3 era, you needed significantly more expensive hardware for comparable performance.
Long-Context Applications Become Viable
The 256K context window opens up a range of application scenarios:
- Codebase analysis: Feed an entire project's source code in one pass
- Long document summarization: Process complete technical documentation or legal contracts
- Multi-turn conversations: Maintain ultra-long conversation history without losing context
- Enhanced RAG: Fit more retrieval results into the context window
Fine-tuning Becomes More Efficient
A hidden benefit of MoE architecture: you can fine-tune only the activated experts rather than all 25.2B parameters. This dramatically reduces fine-tuning VRAM requirements and training time.
New Possibilities for Edge Deployment
The E2B and E4B, combined with architectural optimizations, enable Gemma 4 to run on smartphones and IoT devices. With Google's LiteRT and MediaPipe frameworks, on-device AI is no longer just a proof-of-concept demo.
Want to get your team up to speed on Gemma 4? Book an AI technical workshop — we offer complete training from architecture selection to production deployment.
Frequently Asked Questions (FAQ)
Should I choose Gemma 4's MoE or Dense version?
If your hardware has 16-24 GB VRAM, go with the 26B MoE. Its active parameter count is only 3.8B, delivering faster inference with roughly 3% quality trade-off. If you have 24+ GB VRAM and need maximum quality, choose the 31B Dense.
How long is 256K context in practice?
Approximately 400,000 English words, 200,000 Chinese characters, or one medium-sized project's complete codebase. In practice, inference speed decreases as context length grows, so choose appropriate lengths based on your specific use case.
Does Shared KV Cache affect model quality?
According to Google's ablation experiments, quality loss is negligible. This is because deep-layer KV projections are highly similar to shallow-layer ones — sharing them removes redundancy rather than discarding information.
How does Gemma 4's architecture relate to Gemini 3?
Gemma 4 and Gemini 3 share the same underlying research. Think of Gemini as Google's full-featured internal version, while Gemma is the distilled architecture optimized for open use. MoE, Dual RoPE, and Shared KV Cache all originate from the same research team's work.
Want to learn more about Gemma 4 in practice? Here are related deep dives:
- Gemma 4 Complete Guide — comprehensive coverage of all model specs, deployment, and fine-tuning
- Gemma 4 Hardware Requirements Guide — hardware configuration recommendations from phones to workstations
- Gemma 4 vs Llama 4 vs Qwen 3 Comparison — full-spectrum comparison of the three major open-source models
Have architecture-related technical questions? Reach out to the CloudInsight team and let our AI architecture consultants help you find answers.
Need Professional Cloud Advice?
Whether you're evaluating cloud platforms, optimizing existing architecture, or looking for cost-saving solutions, we can help
Book Free ConsultationRelated Articles
Gemma 4 Complete Guide: The Most Powerful Open Source Model of 2026
Google's Gemma 4 open-source model family in 2026 — Apache 2.0 licensed, four sizes (E2B to 31B), 256K context window, multimodal support. Full analysis of architecture, deployment, fine-tuning, API integration, and enterprise adoption strategies.
AI Dev ToolsGemma 4 API Tutorial: Vertex AI and Google AI Studio Integration Guide
Complete 2026 Gemma 4 API integration tutorial: Google AI Studio for free quick start vs Vertex AI for enterprise deployment. Includes Python code examples, multimodal input, Function Calling, system prompts, and API pricing optimization.
AI Dev ToolsHow to Run Gemma 4 31B on Mac: Complete Apple Silicon Deployment Guide
Complete 2026 guide to running Gemma 4 31B on Apple Silicon Macs: unified memory advantages, M4/M4 Pro/M4 Max hardware recommendations, Ollama vs MLX framework comparison, three budget tiers, installation tutorials, and community benchmarks.