Gemma 4 微調教學:LoRA/QLoRA 實戰,消費級 GPU 也能跑
Gemma 4 微調教學:LoRA/QLoRA 實戰,消費級 GPU 也能跑
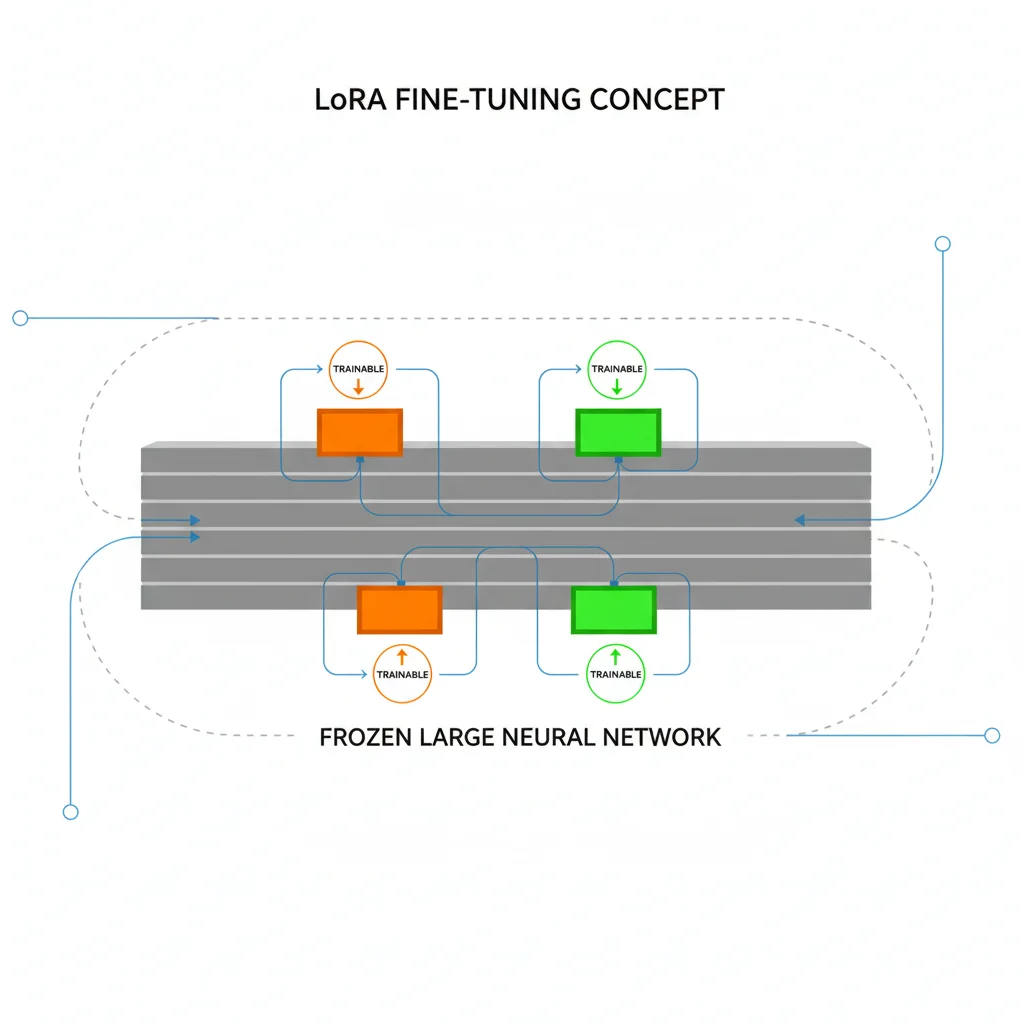
TL;DR: Gemma 4 微調不需要 A100 或 H100。透過 QLoRA 搭配 Unsloth,RTX 4090 單卡就能微調 26B MoE 甚至 31B Dense 模型。只需訓練 0.2% 的參數,記憶體需求從 62GB 降到 16GB 以下,訓練時間數小時內完成。但在動手之前,先確認你真的需要微調——很多場景其實 prompt engineering 就夠了。
你有一個很具體的需求:讓 Gemma 4 用你公司的語氣回答客戶問題、精準分類你行業的專業文件、或是用特定格式產生報告。你試過各種 prompt,效果就是差那麼一點。
這時候,微調就是你的答案。
好消息是,2026 年的微調工具鏈已經成熟到令人驚訝的程度。你不需要租用雲端 GPU 叢集,不需要寫複雜的訓練腳本,一張消費級顯卡加上 Unsloth,就能把 Gemma 4 調校成你的專屬模型。
不確定你的專案該用微調還是 RAG?預約免費 AI 架構諮詢,讓我們的顧問團隊幫你評估最適合的方案。
這篇教學會從頭到尾帶你走一遍完整流程:判斷何時該微調、選擇正確的方法、準備訓練資料、執行微調、評估結果、到最終部署。每一步都有可直接使用的程式碼範例。
想先了解 Gemma 4 的整體概況?請參考 Gemma 4 完整指南。
什麼時候該微調 Gemma 4?
這是最重要的問題,卻也是最常被跳過的。很多人一拿到新模型就想微調,但事實是:2026 年的 Gemma 4 開箱即用能力已經非常強大,大多數以為需要微調的場景,其實好的 prompt engineering 就能解決。
適合微調的場景
特定領域的專業語言——你的行業有大量術語、縮寫、或是一般模型不理解的概念。例如半導體製程文件中的專有名詞,或是醫療病歷中的縮寫。微調能讓模型「內化」這些知識,而不是每次都要在 prompt 中解釋。
一致的輸出格式——你需要模型每次都產出完全相同結構的 JSON、XML、或是特定報告格式。Prompt engineering 可以做到 90%,但微調能推到 99%+ 的一致性。
風格與語氣轉換——把模型調整成你品牌的語氣,例如客服回覆要帶點幽默但不失專業。研究顯示,只需要 200-1,000 筆高品質範例就能有效轉換風格。
降低推理延遲——使用 RAG 時,資料檢索步驟和較長的 context 會增加回應時間。微調後的模型已經「記住」了這些知識,可以直接回答,延遲更低。
在較小模型上達到大模型的效果——一個微調過的 Gemma 4 E4B(4.3B)在特定任務上可能超越未微調的 26B MoE。這意味著更低的部署成本和更快的推理速度。
不需要微調的場景
一般知識問答——Gemma 4 的預訓練資料已經涵蓋了大部分常識。
需要即時更新的資訊——微調後的知識是靜態的。如果你需要回答「今天的股價」,RAG 才是正確方案。
你的資料量太少——少於 50 筆範例很難產生有意義的效果。先嘗試 few-shot prompting。
你還在探索需求——微調是一個「固化」的過程。如果你的需求還在變化,先用 prompt engineering 快速迭代。
我的經驗法則:先用 prompt engineering 達到 80% 的效果,再用微調把最後 20% 補上。 如果 prompt engineering 連 50% 都達不到,問題可能不在模型,而在任務定義。
LoRA vs QLoRA vs Full Fine-tuning:三種方法比較
選擇微調方法是第二個關鍵決定。三種方法各有優劣,以下是完整比較。
Full Fine-tuning(全量微調)
更新模型的所有參數。效果最好,但成本極高——Gemma 4 31B 全量微調需要 4 張 A100 80GB 或更多,訓練時間以天計算。除非你是大公司有專門的 ML 團隊和 GPU 叢集,否則不建議。
LoRA(Low-Rank Adaptation)
凍結原始模型,只在特定層加入小型「適配器矩陣」進行訓練。典型設定下只訓練 0.2-1% 的參數,記憶體需求大幅降低。Gemma 4 26B MoE 用 LoRA 微調大約需要 32-40GB VRAM。
QLoRA(Quantized LoRA)
在 LoRA 的基礎上,把原始模型量化到 4-bit。這是 2026 年最受歡迎的微調方法,因為它把記憶體需求再砍一半以上。Gemma 4 26B MoE 用 QLoRA 只需約 16GB VRAM——一張 RTX 4090 就搞定。
| 比較項目 | Full Fine-tuning | LoRA | QLoRA |
|---|---|---|---|
| 訓練參數比例 | 100% | 0.2-1% | 0.2-1% |
| Gemma 4 31B VRAM 需求 | ~250 GB(4x A100) | ~40 GB | ~18 GB |
| Gemma 4 26B MoE VRAM 需求 | ~200 GB(4x A100) | ~32 GB | ~16 GB |
| Gemma 4 E4B VRAM 需求 | ~35 GB | ~12 GB | ~6 GB |
| 訓練速度(相對) | 1x | 2-3x | 2-4x(Unsloth 加速) |
| 效果(相對) | 最佳 | 接近 Full(~95-98%) | 接近 LoRA(~93-97%) |
| 適用硬體 | 多卡 A100/H100 | A100 / 雙 RTX 4090 | 單卡 RTX 4090 / 3090 |
| 推薦程度 | 除非有充足資源 | 有 40GB+ VRAM | 大多數人的最佳選擇 |
結論:對 99% 的開發者來說,QLoRA 是最實際的選擇。 它在效果、成本、和門檻之間取得了最佳平衡。以下教學也以 QLoRA + Unsloth 為主。
想了解各 Gemma 4 模型的詳細硬體需求?請參考 Gemma 4 硬體需求完整指南。
環境準備:Unsloth + QLoRA 實戰設定
為什麼選 Unsloth?
Unsloth 是 2026 年最受歡迎的微調框架,專門優化了 LoRA/QLoRA 的訓練效率。相比標準的 Hugging Face Transformers + PEFT,Unsloth 能做到:
- 訓練速度快 2 倍(透過自定義 CUDA kernel)
- 記憶體省 70%(智慧型梯度檢查點)
- 原生支援 Gemma 4 全系列(E2B 到 31B)
硬體需求
| 模型 | 最低 VRAM | 建議 VRAM | 建議 GPU |
|---|---|---|---|
| E2B(2.3B) | ~3 GB | 6 GB | RTX 3060 / T4 |
| E4B(4.3B) | ~6 GB | 8 GB | RTX 3070 / T4 |
| 26B MoE | ~14 GB | 18 GB | RTX 4090 / A5000 |
| 31B Dense | ~16 GB | 24 GB | RTX 4090 / A6000 |
以上為 QLoRA 4-bit + gradient checkpointing 的需求。
安裝步驟
# 建立虛擬環境
python -m venv gemma4-finetune
source gemma4-finetune/bin/activate
# 安裝 Unsloth(自動安裝相容版本的 PyTorch、Transformers、PEFT)
pip install unsloth
# 驗證安裝
python -c "from unsloth import FastModel; print('Unsloth ready!')"
如果你在 Google Colab 或 Kaggle 上操作,Unsloth 提供了一鍵安裝指令:
# Colab / Kaggle 專用
%%capture
!pip install unsloth
驗證 GPU 可用
import torch
print(f"CUDA available: {torch.cuda.is_available()}")
print(f"GPU: {torch.cuda.get_device_name(0)}")
print(f"VRAM: {torch.cuda.get_device_properties(0).total_mem / 1024**3:.1f} GB")
正在評估要把 AI 微調能力導入你的團隊?預約架構諮詢,我們能幫你規劃從硬體採購到模型部署的完整策略。
資料準備:如何格式化你的訓練資料
資料品質決定微調成敗。垃圾進,垃圾出——這在微調領域尤其明顯。
Gemma 4 對話格式
Gemma 4 使用標準的 messages 格式,支援 system、user、model 三種角色:
{
"messages": [
{
"role": "system",
"content": "你是一位專業的半導體製程工程師,回答時使用繁體中文,語氣專業但易懂。"
},
{
"role": "user",
"content": "什麼是 EUV 微影技術?"
},
{
"role": "model",
"content": "EUV(Extreme Ultraviolet Lithography)是使用 13.5nm 波長極紫外光的先進微影技術..."
}
]
}
注意:Gemma 4 用 model 而不是 assistant 作為助手角色名稱。Unsloth 和 TRL 會自動處理 chat template 的轉換,你只需要準備好 JSON 格式即可。
資料量建議
不同任務需要的資料量差異很大:
| 任務類型 | 建議筆數 | 說明 |
|---|---|---|
| 風格/語氣轉換 | 200-1,000 | 高品質優先,每筆要展現目標風格 |
| 分類任務 | 500-5,000 | 每個類別至少 50-100 筆,平衡分布 |
| 領域知識 | 10,000-50,000 | 涵蓋領域內的主要概念和邊界情況 |
| 指令遵循 | 5,000-20,000 | 多樣化的指令和回應 |
資料清洗技巧
import json
def validate_and_clean(dataset_path):
clean_data = []
with open(dataset_path, 'r', encoding='utf-8') as f:
data = json.load(f)
for i, item in enumerate(data):
# 檢查必要欄位
if 'messages' not in item:
print(f"⚠ Row {i}: missing 'messages' field, skipped")
continue
messages = item['messages']
# 確保至少有 user + model 一輪對話
roles = [m['role'] for m in messages]
if 'user' not in roles or 'model' not in roles:
print(f"⚠ Row {i}: missing user or model turn, skipped")
continue
# 移除空白回應
messages = [m for m in messages if m['content'].strip()]
# 檢查回應長度(太短可能沒有訓練價值)
model_responses = [m for m in messages if m['role'] == 'model']
if any(len(m['content']) < 10 for m in model_responses):
print(f"⚠ Row {i}: model response too short, skipped")
continue
clean_data.append({'messages': messages})
print(f"✓ {len(clean_data)}/{len(data)} samples passed validation")
return clean_data
從現有格式轉換
如果你有 Alpaca 格式(instruction / input / output)的資料,轉換很簡單:
def alpaca_to_gemma4(alpaca_data):
converted = []
for item in alpaca_data:
messages = []
user_content = item['instruction']
if item.get('input'):
user_content += f"\n\n{item['input']}"
messages.append({"role": "user", "content": user_content})
messages.append({"role": "model", "content": item['output']})
converted.append({"messages": messages})
return converted
手把手微調流程:從載入模型到訓練完成
準備好了?以下是完整的 QLoRA 微調流程,以 Gemma 4 26B MoE 為例。
Step 1:載入模型與 QLoRA 設定
from unsloth import FastModel
from unsloth.chat_templates import get_chat_template
# 載入 Gemma 4 26B MoE,啟用 4-bit 量化
model, tokenizer = FastModel.from_pretrained(
model_name="unsloth/gemma-4-27b-it", # Unsloth 優化版
max_seq_length=4096, # 根據你的資料長度調整
load_in_4bit=True, # QLoRA 核心:4-bit 量化
dtype=None, # 自動偵測最佳 dtype
)
# 設定 chat template
tokenizer = get_chat_template(tokenizer, chat_template="gemma-4")
print(f"Model loaded! VRAM used: {torch.cuda.memory_allocated()/1024**3:.1f} GB")
Step 2:加入 LoRA 適配器
model = FastModel.get_peft_model(
model,
r=16, # LoRA rank,16 是好的起點
lora_alpha=32, # 通常設為 2x rank
lora_dropout=0.05, # 輕微 dropout 防止過擬合
target_modules=[ # 要加 LoRA 的層
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",
],
use_gradient_checkpointing="unsloth", # 省 30% VRAM
)
# 查看可訓練參數
trainable_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
total_params = sum(p.numel() for p in model.parameters())
print(f"Trainable: {trainable_params:,} / {total_params:,} ({100*trainable_params/total_params:.2f}%)")
# 輸出約:Trainable: 54,525,952 / 25,200,000,000 (0.22%)
Step 3:載入訓練資料
from datasets import load_dataset
# 從本地 JSON 檔載入
dataset = load_dataset("json", data_files="train_data.json", split="train")
# 或從 Hugging Face Hub 載入
# dataset = load_dataset("your-username/your-dataset", split="train")
# 格式化為 Gemma 4 chat format
def format_chat(example):
text = tokenizer.apply_chat_template(
example["messages"],
tokenize=False,
add_generation_prompt=False,
)
return {"text": text}
dataset = dataset.map(format_chat)
print(f"Dataset size: {len(dataset)} samples")
Step 4:設定訓練參數並開始訓練
from trl import SFTTrainer
from transformers import TrainingArguments
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=dataset,
args=TrainingArguments(
output_dir="./gemma4-finetuned",
# 訓練參數
num_train_epochs=3, # 3 輪通常足夠
per_device_train_batch_size=2, # RTX 4090 可用 2
gradient_accumulation_steps=4, # 有效 batch size = 2 x 4 = 8
# 學習率
learning_rate=2e-4, # QLoRA 建議 1e-4 到 3e-4
lr_scheduler_type="cosine", # cosine 衰減效果好
warmup_ratio=0.05, # 5% warmup
# 精度與效能
fp16=not torch.cuda.is_bf16_supported(),
bf16=torch.cuda.is_bf16_supported(),
# 儲存與日誌
logging_steps=10,
save_strategy="steps",
save_steps=100,
save_total_limit=3, # 只保留最近 3 個 checkpoint
# 其他
seed=42,
optim="adamw_8bit", # 8-bit Adam 省記憶體
weight_decay=0.01,
max_grad_norm=1.0,
),
dataset_text_field="text",
max_seq_length=4096,
)
# 開始訓練!
print("Starting training...")
trainer.train()
print("Training complete!")
訓練參數建議
| 參數 | 建議值 | 說明 |
|---|---|---|
LoRA rank (r) | 8-32 | 越高效果越好但佔更多記憶體,16 是甜蜜點 |
lora_alpha | 2x rank | 控制 LoRA 更新的縮放比例 |
| Learning rate | 1e-4 到 3e-4 | QLoRA 比 Full FT 需要更高的學習率 |
| Epochs | 1-5 | 資料少(<1000)用 3-5,資料多(>10000)用 1-2 |
| Batch size | 越大越好 | 受 VRAM 限制,用 gradient accumulation 補 |
max_seq_length | 依資料而定 | 太長浪費記憶體,太短截斷資料 |
提示: 如果訓練 loss 在前幾步就降到很低然後不動了,可能是學習率太高或資料太簡單。如果 loss 震盪不收斂,試著降低學習率或增加 warmup。
評估微調結果:怎麼知道你的模型變好了
微調完成不代表成功。沒有嚴格的評估,你不知道模型是真的學到了有用的知識,還是只是「背答案」(過擬合)。
基本評估:Training Loss 曲線
import matplotlib.pyplot as plt
# 從 trainer 取得訓練日誌
logs = trainer.state.log_history
steps = [log['step'] for log in logs if 'loss' in log]
losses = [log['loss'] for log in logs if 'loss' in log]
plt.figure(figsize=(10, 5))
plt.plot(steps, losses)
plt.xlabel('Steps')
plt.ylabel('Training Loss')
plt.title('Gemma 4 Fine-tuning Loss Curve')
plt.savefig('training_loss.png')
健康的 loss 曲線應該:先快速下降、然後平穩收斂。如果 loss 降到接近 0,幾乎可以確定過擬合了。
進階評估:人工品質檢查
自動化指標有其限制。最可靠的方式還是人工檢查:
# 載入微調後的模型
from unsloth import FastModel
model, tokenizer = FastModel.from_pretrained(
"gemma4-finetuned/checkpoint-300",
max_seq_length=4096,
load_in_4bit=True,
)
# 測試推理
test_prompts = [
"你的測試問題 1",
"你的測試問題 2",
"你的邊界情況測試",
]
for prompt in test_prompts:
messages = [{"role": "user", "content": prompt}]
inputs = tokenizer.apply_chat_template(
messages, tokenize=True, add_generation_prompt=True,
return_tensors="pt"
).to("cuda")
outputs = model.generate(inputs, max_new_tokens=512, temperature=0.7)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(f"Q: {prompt}")
print(f"A: {response}\n")
常見陷阱
過擬合的徵兆——模型對訓練資料中出現過的問題回答完美,但對稍微不同的問題表現很差。解法:增加資料量、降低 epoch 數、增加 dropout。
災難性遺忘——微調後模型失去了原本的通用能力。解法:混入一定比例的通用指令資料(例如 10-20%)。
格式退化——模型開始產生奇怪的格式或重複內容。解法:檢查訓練資料中是否有格式異常,降低學習率。
匯出與部署微調模型

微調完成、評估通過後,下一步是把模型匯出成可部署的格式。
儲存 LoRA 適配器
最輕量的方式是只儲存 LoRA 適配器(通常只有幾十 MB):
# 儲存 LoRA 適配器
model.save_pretrained("gemma4-lora-adapter")
tokenizer.save_pretrained("gemma4-lora-adapter")
# 上傳到 Hugging Face Hub(可選)
# model.push_to_hub("your-username/gemma4-custom-adapter")
合併為完整模型
如果你想要一個獨立的模型檔案,可以把 LoRA 適配器合併回基礎模型:
# 合併 LoRA 到基礎模型
model.save_pretrained_merged(
"gemma4-merged",
tokenizer,
save_method="merged_16bit", # 或 "merged_4bit"
)
匯出為 GGUF 格式(適用 Ollama / llama.cpp)
這是本地部署最常用的格式:
# 匯出為 GGUF Q4_K_M 量化
model.save_pretrained_gguf(
"gemma4-finetuned-gguf",
tokenizer,
quantization_method="q4_k_m",
)
匯出的 GGUF 檔案可以直接用 Ollama 載入:
# 建立 Modelfile
echo 'FROM ./gemma4-finetuned-gguf/unsloth.Q4_K_M.gguf' > Modelfile
# 在 Ollama 中建立自訂模型
ollama create my-gemma4 -f Modelfile
# 測試
ollama run my-gemma4 "你的測試 prompt"
關於 Gemma 4 本地部署的完整教學,包括 Ollama、vLLM、Docker 等多種方式,請參考 Gemma 4 本地部署教學。
想把微調模型部署到生產環境?聯繫我們的 AI 架構團隊,從 GPU 選型到 API 服務化,我們都能提供專業建議。
常見問題(FAQ)
Q1:微調 Gemma 4 26B MoE 需要多長時間?
在 RTX 4090 上使用 QLoRA,1,000 筆訓練資料、3 個 epoch 大約需要 2-4 小時。資料量越大、序列長度越長、batch size 越小,時間越長。E4B(4.3B)同樣條件下大約 30-60 分鐘。
Q2:QLoRA 微調的效果和全量微調差多少?
根據社群基準測試,QLoRA 在大多數任務上能達到全量微調 93-97% 的效果。對於特定領域任務(分類、資訊抽取),差距通常更小。除非你有非常充足的 GPU 資源,否則 QLoRA 的性價比遠高於全量微調。
Q3:可以在 Google Colab 免費版上微調嗎?
可以,但有限制。Colab 免費版提供 T4 GPU(16GB VRAM),足夠微調 E2B(2.3B)和 E4B(4.3B)。26B MoE 在 T4 上很勉強,需要極小的 batch size 和非常短的序列長度。建議使用 Colab Pro(A100 40GB)或本地 RTX 4090。
Q4:微調後的模型可以商用嗎?
可以。Gemma 4 採用 Apache 2.0 授權,這是最寬鬆的開源授權之一。你可以自由使用微調後的模型進行商業用途,包括販售、嵌入產品、或提供 API 服務,沒有限制。
準備好開始微調了嗎?如果你需要更進階的技術指導——例如多 GPU 分散式訓練、DPO/RLHF 對齊、或是生產級別的模型服務化——預約我們的 AI 開發諮詢。
延伸閱讀
相關文章
Gemma 4 完整指南:2026 年最強開源模型從入門到實戰
2026 年 Google 發布 Gemma 4 開源模型,Apache 2.0 授權、四種尺寸(E2B 到 31B)、256K context window、多模態支援。完整解析架構、部署、微調、API 串接與企業導入策略。
AI 開發工具Gemma 4 本地部署教學:Ollama、LM Studio、Unsloth 三種方式完整攻略
2026 年如何在本地跑 Gemma 4?完整教學三種部署方式:Ollama 五分鐘快速上手、LM Studio 圖形化零門檻、Unsloth 進階推理+微調。含硬體需求、量化選擇與常見問題排除。
AI 開發工具Gemma 4 vs Llama 4 vs Qwen 3.5:2026 開源模型三巨頭完整比較
2026 年三大開源模型 Gemma 4、Llama 4、Qwen 3.5 完整比較:Benchmark 實測、推理速度、授權條款(Apache 2.0 vs Llama License)、中文能力、硬體需求與選型決策指南。