Gemma 4 架構解析:MoE、Dual RoPE、256K Context 技術深度剖析
Gemma 4 架構解析:MoE、Dual RoPE、256K Context 技術深度剖析
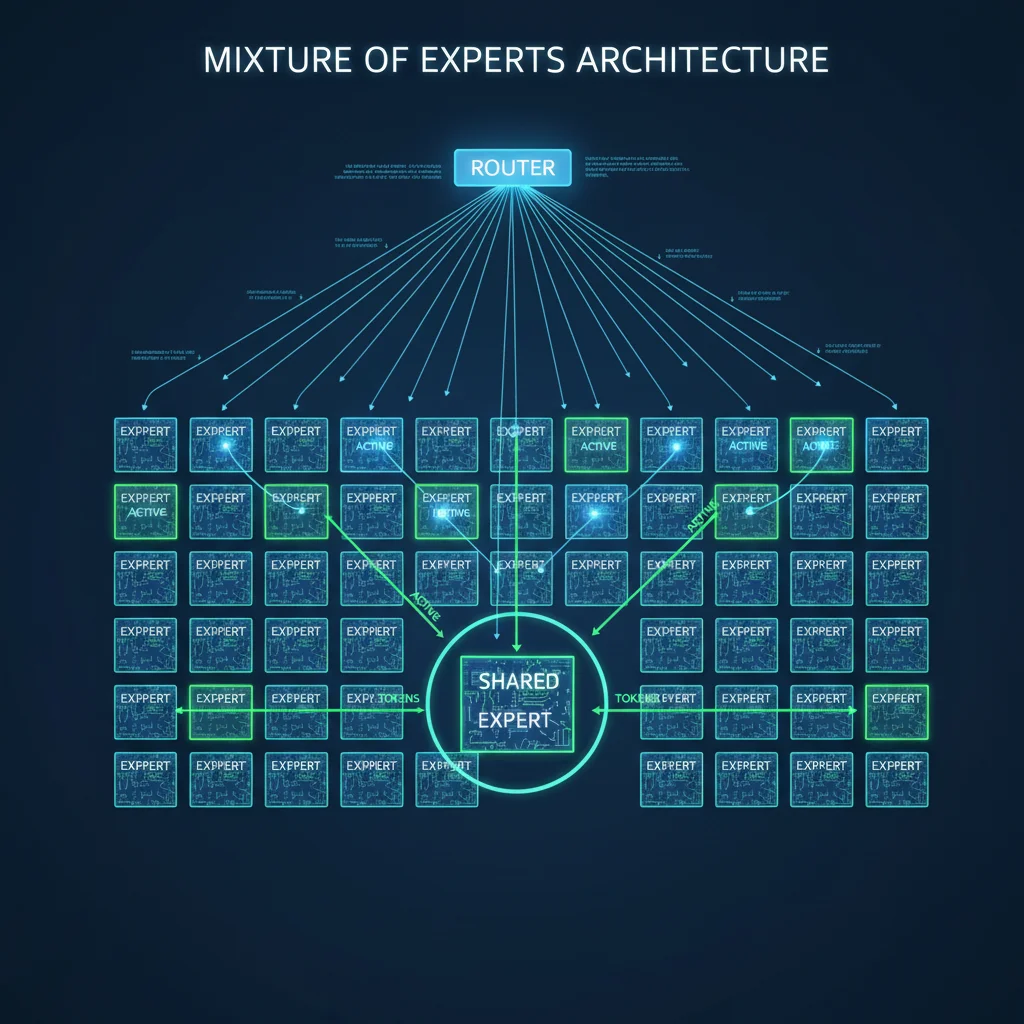
TL;DR: Gemma 4 的 26B MoE 變體配備 128 個專家,每次推理只啟動 8 個加 1 個共享專家,活躍參數僅 3.8B 卻達到 31B Dense 版 97% 的效能。透過 Dual RoPE(標準 RoPE + p-RoPE)實現 256K context window,Shared KV Cache 讓最後 N 層重用前面的 KV 投射,省下大量記憶體和計算。這些架構創新讓 AIME 分數從 Gemma 3 的 20.8% 飆到 89.2%。
你有沒有想過,一個只啟動 3.8B 參數的模型,怎麼可能打敗 31B 參數的完整模型?答案藏在 Gemma 4 的架構設計裡。
Google DeepMind 在 2026 年 4 月發布的 Gemma 4,不是簡單的「把模型變大」。他們從根本改變了模型的運作方式——用更聰明的路由取代更多的參數,用更精巧的注意力機制取代暴力的全域計算。
這篇文章會拆解 Gemma 4 的四大架構創新,告訴你為什麼這些設計決策讓它成為 2026 年最具影響力的開源模型。如果你還不熟悉 Gemma 4 的整體概況,建議先看 Gemma 4 完整指南。
正在評估 Gemma 4 的架構是否適合你的應用場景?預約免費 AI 架構諮詢,讓我們的團隊幫你做技術評估。
Gemma 4 模型架構總覽:Dense vs MoE 兩條路線
Gemma 4 家族提供兩種根本不同的架構路線:Dense(稠密)和 MoE(混合專家)。這不是單純的大小區別,而是完全不同的設計哲學。
Dense 架構包含 E2B(2.3B)、E4B(4.3B)和 31B 三款模型。每次推理時,所有參數都會參與計算。31B Dense 是旗艦版,MMLU Pro 85.2%、AIME 89.2%,但需要約 18 GB VRAM。
MoE 架構只有一款:26B A4B。總參數量 25.2B,但每次推理只啟動 3.8B 參數。MMLU Pro 82.6%、AIME 88.3%——用不到 31B Dense 八分之一的運算量,達到 97% 的效能。
兩條路線服務不同需求。如果你追求極致品質且硬體充足,選 31B Dense。如果你需要在有限硬體上獲得最佳性價比,26B MoE 是更聰明的選擇。
| 特性 | Dense(31B) | MoE(26B A4B) |
|---|---|---|
| 總參數 | 31B | 25.2B |
| 活躍參數 | 31B | 3.8B |
| AIME 2026 | 89.2% | 88.3% |
| MMLU Pro | 85.2% | 82.6% |
| 最低 VRAM(Q4) | ~18 GB | ~16 GB |
| 推理速度 | 基準 | 快 3-4 倍 |
接下來,我們深入看 MoE 架構的核心設計——128 個專家是怎麼分工合作的。
Mixture of Experts(MoE):128 個專家怎麼分工
MoE 不是新概念,但 Gemma 4 的實作方式有幾個關鍵突破。
128 個小專家 + 1 個共享專家
傳統 MoE 模型通常用 8-16 個大專家。Gemma 4 反其道而行——用 128 個小專家加上 1 個共享專家。為什麼?
更細粒度的專業分工。 128 個小專家意味著每個專家可以高度專精於特定的知識領域或語言模式。路由器(Router)為每個 token 評分所有 128 個專家,然後選出得分最高的 8 個來處理。
共享專家是關鍵設計。 那個共享專家不參與路由選擇——它永遠被啟動。Google 把它設計成普通專家的三倍大小,用來存放通用知識。你可以把它想像成公司的「通識部門」,而 128 個小專家是各個專業部門。每次處理一個 token,通識部門一定會參與,再加上 8 個最相關的專業部門。
路由機制怎麼運作
路由的核心是一個線性層加 softmax。每個 token 的隱藏狀態經過路由器,產生 128 個分數。取 top-8 作為這個 token 要送往的專家。
這裡有個重要的效率考量:雖然總參數是 25.2B,但因為每次只啟動 8 個專家加 1 個共享專家,活躍參數只有 3.8B。這代表:
- 推理速度:快,因為實際計算量小
- 記憶體使用:載入時需要全部 25.2B 參數,但運算記憶體只需要 3.8B 的量
- 品質保證:128 個專家的多樣性確保了對各種輸入的覆蓋率
我第一次看到 26B MoE 在 AIME 拿下 88.3% 的時候,老實說有點被嚇到。3.8B 的活躍參數,居然跟 31B Dense 只差不到一個百分點?這驗證了一個觀點:模型品質不完全取決於參數量,更取決於參數的使用效率。
想了解在你的硬體上跑 MoE 模型需要什麼配置?可以參考 Gemma 4 硬體需求指南。
Dual RoPE:256K Context Window 的秘密武器
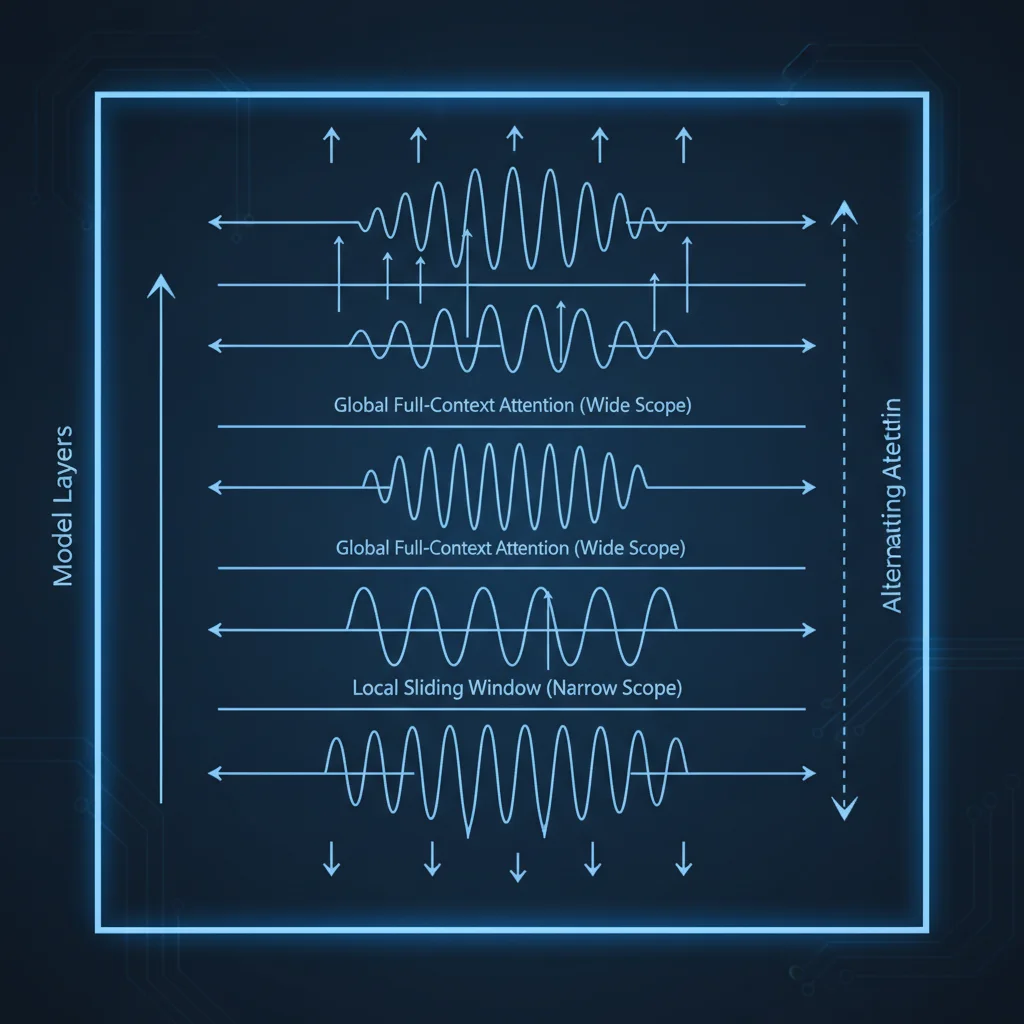
Context window 從 Gemma 3 的 128K 擴展到 256K,靠的不是暴力擴大位置編碼的範圍。Gemma 4 用了一個更優雅的方案:Dual RoPE。
交替式注意力層
Gemma 4 的 decoder 層在兩種注意力模式之間交替:
- 局部滑動窗口注意力(Sliding Window Attention):每層只關注 512-1024 個鄰近 token。速度快、記憶體省,適合處理局部上下文。
- 全域注意力(Global Attention):關注整個 context 中的所有 token。計算量大,但能捕捉長距離依賴。
兩種層交替排列,最後一層永遠是全域注意力——確保模型的最終輸出有完整的全局視野。
為什麼需要兩種 RoPE?
問題來了:標準 RoPE(Rotary Position Embedding)在超長距離時會出現品質退化。當 token 之間的距離超過訓練時見過的最大距離,位置編碼的外推能力就會下降。
Gemma 4 的解決方案是雙軌制:
- 滑動窗口層:使用標準 RoPE。因為窗口本身就限制了 token 距離在 512-1024 以內,不存在外推問題。
- 全域注意力層:使用 Proportional RoPE(p-RoPE)。p-RoPE 透過調整頻率分佈,讓位置編碼在超長距離下仍保持穩定。
這就是 Dual RoPE——同一個模型裡用兩套不同的位置編碼策略,各自服務於不同類型的注意力層。
實際效果
256K context window 意味著你可以一次塞入大約 20 萬字的中文內容。對於需要處理完整程式碼倉庫、長篇文件、或多輪對話歷史的場景,這是實實在在的能力提升。
更重要的是,品質不會因為 context 變長而嚴重退化。這是 Dual RoPE 相比單純擴大 RoPE base frequency 的核心優勢。
Shared KV Cache:推理加速的關鍵設計
如果說 MoE 解決的是「訓練效率」問題,Shared KV Cache 解決的就是「推理效率」問題。這是 Gemma 4 在實際部署層面最實用的創新之一。
KV Cache 是什麼?為什麼它是瓶頸?
在 Transformer 推理時,每一層都需要計算 Key 和 Value 矩陣。這些矩陣會被快取起來(KV Cache),讓模型在生成下一個 token 時不用重複計算之前的 token。
問題在於,256K 的 context window 意味著 KV Cache 會變得非常龐大。每一層都要存儲自己的 K 和 V,層數一多,記憶體就爆了。
Gemma 4 的解決方案
Gemma 4 引入了 Shared KV Cache:模型最後 N 層不再自己計算 K 和 V 投射。它們直接重用前面最近一個非共享層的 KV 張量。
關鍵細節:重用時會區分注意力類型——滑動窗口層只會重用其他滑動窗口層的 KV,全域注意力層只會重用其他全域注意力層的 KV。這保證了不同類型的注意力機制不會互相干擾。
效能影響
- 記憶體節省:少了 N 層的 KV 投射參數,直接省下對應的記憶體
- 計算節省:跳過了 KV 投射的矩陣乘法,推理速度提升
- 品質影響:Google 的消融實驗顯示,品質損失可以忽略不計
對於跑 256K token 推理的團隊來說,這個設計是實打實的省錢利器。搭配量化技術,26B MoE 在 16 GB VRAM 的消費級 GPU 上就能順暢運行。
Per-Layer Embeddings(PLE)
值得一提的還有 Per-Layer Embeddings——一個額外的嵌入表,為每一層 decoder 提供一個小型殘差信號。這讓模型可以為不同層學習不同的 token 表示偏移,進一步提升了各層的專業化程度。
想在現有基礎設施上部署 Gemma 4?聯繫我們的 AI 架構團隊,獲取客製化的部署方案和成本估算。
從 Gemma 3 到 Gemma 4:架構演進對比

把 Gemma 3 和 Gemma 4 的架構放在一起看,你會發現這不是簡單的版本升級,而是設計哲學的根本轉變。
架構差異一覽
| 特性 | Gemma 3 | Gemma 4 |
|---|---|---|
| 架構類型 | 純 Dense | Dense + MoE 雙軌 |
| 最大模型 | 27B | 31B Dense / 26B MoE |
| Context Window | 128K | 256K |
| 位置編碼 | 標準 RoPE | Dual RoPE(標準 + p-RoPE) |
| KV Cache | 每層獨立 | 最後 N 層共享 |
| GQA 比例 | 較高 KV head 數 | 8 Query : 1 KV(更激進壓縮) |
| 專家系統 | 無 | 128 專家 + 1 共享專家 |
| Per-Layer Embeddings | 無 | 有 |
| 授權 | Google Terms of Use | Apache 2.0 |
| AIME 2026 | 20.8% | 89.2%(31B) |
| MMLU Pro | ~70% | 85.2%(31B) |
最關鍵的三個變化
第一,MoE 的引入。 Gemma 3 全系列都是 Dense 架構。Gemma 4 首次提供 MoE 選項,讓開發者可以用更少的運算資源獲得接近旗艦水準的效能。這對預算有限的團隊和邊緣部署場景意義重大。
第二,注意力機制的優化。 Gemma 4 把 GQA(Grouped Query Attention)推到了更激進的比例——8 個 Query head 共享 1 個 KV head。這配合 Shared KV Cache,大幅壓縮了推理時的記憶體需求。
第三,context window 翻倍。 從 128K 到 256K,但不是靠蠻力。Dual RoPE 的設計讓這個擴展在保持品質的前提下完成。這是真正的工程突破。
E2B 的表現特別值得注意。社群測試確認,這個只有 2.3B 參數的小模型,在多個任務上超過了 Gemma 3 的 27B 版本。參數量小了 12 倍,效能反而更好。這充分說明了架構創新比簡單堆參數更有效。
想比較 Gemma 4 和其他競爭對手的架構差異?請看 Gemma 4 vs Llama 4 vs Qwen 3 對比分析。
這些架構創新對開發者意味著什麼
看完架構設計,你可能會想:這些技術細節跟我的實際工作有什麼關係?
部署成本大幅降低
MoE + Shared KV Cache 的組合效果是:你可以在一張 RTX 4090(24 GB VRAM)上跑 26B MoE 的量化版本,獲得接近 31B Dense 的品質。在 Gemma 3 時代,你需要更昂貴的硬體才能達到類似效能。
長文本應用變得可行
256K context window 打開了一系列應用場景:
- 程式碼倉庫分析:一次塞入整個專案的程式碼
- 長篇文件摘要:處理完整的技術文件或法律合約
- 多輪對話:維持超長的對話歷史不丟失上下文
- RAG 增強:在 context 中放入更多檢索結果
微調變得更高效
MoE 架構的一個隱藏好處:你可以只微調被啟動的專家,不用動全部 25.2B 參數。這大幅降低了微調的 VRAM 需求和訓練時間。
邊緣部署的新可能
E2B 和 E4B 搭配架構優化,讓 Gemma 4 可以在手機和 IoT 裝置上運行。結合 Google 推出的 LiteRT 和 MediaPipe 框架,on-device AI 不再只是展示用的概念驗證。
想讓你的團隊快速上手 Gemma 4?預約 AI 技術工作坊,我們提供從架構選型到實際部署的完整培訓。
常見問題(FAQ)
Gemma 4 的 MoE 和 Dense 版本該怎麼選?
如果你的硬體 VRAM 在 16-24 GB 之間,選 26B MoE。它的活躍參數只有 3.8B,推理速度更快,而品質只損失約 3%。如果你有 24 GB 以上的 VRAM 且追求最高品質,選 31B Dense。
256K context window 實際上有多長?
大約等於 20 萬字中文、40 萬字英文、或一個中型專案的完整程式碼。實際使用中,推理速度會隨 context 長度增加而下降,建議根據場景需求選擇合適的長度。
Shared KV Cache 會影響模型品質嗎?
根據 Google 的消融實驗,品質損失可以忽略不計。這是因為深層的 KV 投射和淺層高度相似——共享它們等於去除冗餘,而不是丟棄資訊。
Gemma 4 的架構和 Gemini 3 有什麼關係?
Gemma 4 和 Gemini 3 共享底層研究技術。你可以把 Gemini 想像成 Google 內部的全功能版,Gemma 是從中提煉出最適合開放使用的架構。MoE、Dual RoPE、Shared KV Cache 這些設計都源自同一個研究團隊的成果。
想了解更多 Gemma 4 的實戰應用?以下是相關的深度文章:
- Gemma 4 完整指南:從入門到實戰——涵蓋所有模型規格、部署、微調的完整指南
- Gemma 4 硬體需求指南——從手機到工作站的硬體配置建議
- Gemma 4 vs Llama 4 vs Qwen 3 對比分析——三大開源模型的全方位比較
有架構相關的技術問題?聯繫 CloudInsight 團隊,讓我們的 AI 架構顧問為你解答。
相關文章
Gemma 4 完整指南:2026 年最強開源模型從入門到實戰
2026 年 Google 發布 Gemma 4 開源模型,Apache 2.0 授權、四種尺寸(E2B 到 31B)、256K context window、多模態支援。完整解析架構、部署、微調、API 串接與企業導入策略。
AI 開發工具Gemma 4 API 串接教學:Vertex AI 與 Google AI Studio 實戰
2026 年 Gemma 4 API 串接完整教學:Google AI Studio 免費快速上手 vs Vertex AI 企業級部署。含 Python 程式碼範例、多模態輸入、Function Calling、系統提示設定與 API 定價優化策略。
AI 開發工具Gemma 4 31B 在 Mac 上怎麼跑?Apple Silicon 完整部署指南
2026 年在 Apple Silicon Mac 上跑 Gemma 4 31B 的完整指南:統一記憶體優勢、M4/M4 Pro/M4 Max 硬體配置建議、Ollama vs MLX 框架比較、三種預算方案、安裝教學與社群實測數據。